
Now, this is really small potatoes compared to this [1]:

References
- Dominique Thiebaut, 2D-Packing Images on a Large Scale, INFOCOMP 2013 : The Third International Conference on Advanced Communications and Computation
---- 42 PARAMETER data %%% data set with 12 items cost hours people Rome 1000 5 5 Venice 200 1 10 Torin 500 3 2 Genova 700 7 8 Rome2 1020 5 6 Venice2 220 1 10 Torin2 520 3 2 Genova2 720 7 4 Rome3 1050 5 5 Venice3 250 1 8 Torin3 550 3 8 Genova3 750 7 8
sets
i 'items' /Rome,Venice,Torin,Genova,Rome2,Venice2, Torin2,Genova2,Rome3,Venice3,Torin3,Genova3 / k 'objectives' /cost,hours,people,items/ ; table data(i,k) cost hours people Rome 1000 5 5 Venice 200 1 10 Torin 500 3 2 Genova 700 7 8 Rome2 1020 5 6 Venice2 220 1 10 Torin2 520 3 2 Genova2 720 7 4 Rome3 1050 5 5 Venice3 250 1 8 Torin3 550 3 8 Genova3 750 7 8 ; data(i,'items') = 1; parameter UpperLimit(k) / cost 10000 hours 100 people 50 /; * if zero or not listed use INF upperLimit(k)$(UpperLimit(k)=0) = INF; parameter sign(k) 'sign: +1:min, -1:max' / (cost,hours,people) +1 items -1 /; |
*---------------------------------------------
* Basic Model *--------------------------------------------- parameter c(k) 'objective coefficient'; variable z 'total single obj'; positive variable f(k) 'obj values'; binary variable x(i) 'select item' equations scalobj 'scalarized objective' objs(k) ; scalobj.. z =e= sum(k, c(k)*f(k)); objs(k).. f(k) =e= sum(i, data(i,k)*x(i)); * some objs have an upper limit f.up(k) = upperLimit(k); option optcr=0,limrow=0,limcol=0,solprint=silent,solvelink=5; *--------------------------------------------- * find lower and upper limits of each objective *--------------------------------------------- model m0 'initial model to find box' /all/; parameter fbox(k,*) 'new bounds on objectives'; alias(k,obj); loop(obj, c(obj) = 1; solve m0 minimizing z using mip; fbox(obj,'min') = z.l; solve m0 maximizing z using mip; fbox(obj,'max') = z.l; c(obj) = 0; ); display upperLimit,fbox; * range = max - min fbox(k,'range') = fbox(k,'max')-fbox(k,'min'); * tighten objectives f.lo(k) = fbox(k,'min'); f.up(k) = fbox(k,'max'); |
---- 81 PARAMETER UpperLimit cost 10000.000, hours 100.000, people 50.000, items +INF ---- 81 PARAMETER fbox new bounds on objectives max cost 6810.000 hours 45.000 people 50.000 items 9.000
*---------------------------------------------
* MOIP algorithm *--------------------------------------------- sets maxsols /sol1*sol1000/ sols(maxsols) 'found solutions' ; binary variable delta(maxsols,k) 'count solutions that are better'; equation nondominated1(maxsols,k) nondominated2(maxsols,k) atleastone(maxsols) cut(maxsols) ; parameter solstore(maxsols,*) M(k) 'big-M values' ; M(k) = fbox(k,'range'); scalar tol 'tolerance: improve obj by this much' /1/; * initialize solstore(maxsols,i) = 0; nondominated1(sols,k)$(sign(k)=+1).. f(k) =l= solstore(sols,k)-tol + (M(k)+tol)*(1-delta(sols,k)); nondominated2(sols,k)$(sign(k)=-1).. f(k) =g= solstore(sols,k)+tol - (M(k)+tol)*(1-delta(sols,k)); atleastone(sols).. sum(k, delta(sols,k)) =g= 1; cut(sols).. sum(i, (2*solstore(sols,i)-1)*x(i)) =l= sum(i,solstore(sols,i)) - 1; * initialize to empty set sols(maxsols) = no; * set weights to 1 (adapt for min/max) c(k) = sign(k); scalar ok /1/; model m1 /all/; loop(maxsols$ok, solve m1 minimizing z using mip; * optimal or integer solution found? ok = 1$(m1.modelstat=1 or m1.modelstat=8); if(ok, sols(maxsols) = yes; solstore(maxsols,k) = round(f.l(k)); solstore(maxsols,i) = round(x.l(i)); ); ); display solstore; |

---- 42 PARAMETER data %%% data set with 12 items cost hours people Rome 1000 5 5 Venice 200 1 10 Torin 500 3 2 Genova 700 7 8 Rome2 1020 5 6 Venice2 220 1 10 Torin2 520 3 2 Genova2 720 7 4 Rome3 1050 5 5 Venice3 250 1 8 Torin3 550 3 8 Genova3 750 7 8
 |
| Vilfredo Pareto [2] |
sets
i 'items' /Rome,Venice,Torin,Genova,Rome2,Venice2, Torin2,Genova2,Rome3,Venice3,Torin3,Genova3 / k 'objectives' /cost,hours,people,items/ s 'solution points' /s1*s4096/ ; * * check if set s is large enough * scalar size 'size needed for set s'; size = 2**card(i); abort$(card(s) * * generate all combinations * sets base 'used in next set' /no,yes/ ps0(s,i,base) / system.powersetRight / ps(s,i) 'power set' ; ps(s,i) = ps0(s,i,'yes'); display ps; |
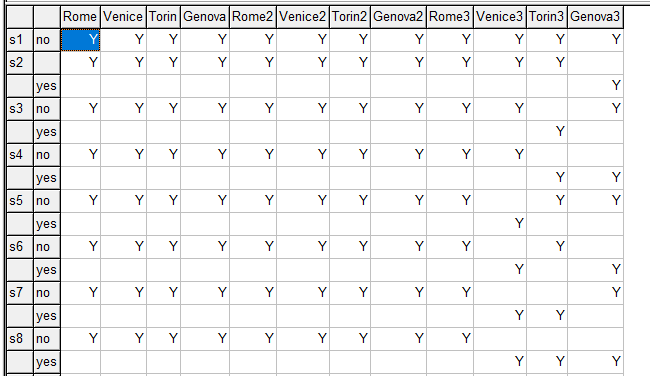 |
| ps0 with second index pivoted |
 |
| Set ps |
 |
| Bottom of set ps |
*
* make a parameter out of this * parameter x(s,i) 'solutions'; x(s,i) = ps(s,i); * make sure row 1 exists: introduce an EPS x(s,i)$(ord(s)=1 and ord(i)=1) = eps; display x; |
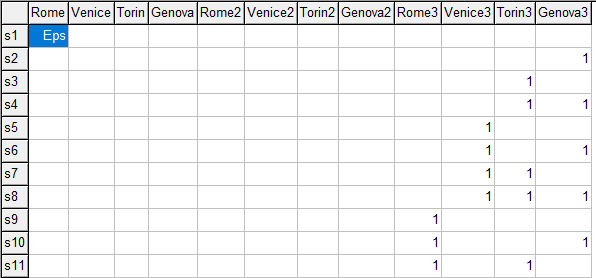 |
| Parameter x with EPS value |
table data(i,k) '### data set with 12 items'
cost hours people Rome 1000 5 5 Venice 200 1 10 Torin 500 3 2 Genova 700 7 8 Rome2 1020 5 6 Venice2 220 1 10 Torin2 520 3 2 Genova2 720 7 4 Rome3 1050 5 5 Venice3 250 1 8 Torin3 550 3 8 Genova3 750 7 8 ; data(i,'items') = 1; parameter f(s,k) 'objective values'; f(s,k) = sum(i, data(i,k)*x(s,i)); display f; |
---- 56 PARAMETER f objective values cost hours people items s1 EPS EPS EPS EPS s2 750.000 7.000 8.000 1.000 s3 550.000 3.000 8.000 1.000 s4 1300.000 10.000 16.000 2.000 s5 250.000 1.000 8.000 1.000 s6 1000.000 8.000 16.000 2.000 s7 800.000 4.000 16.000 2.000 s8 1550.000 11.000 24.000 3.000 s9 1050.000 5.000 5.000 1.000 s10 1800.000 12.000 13.000 2.000 . . . s4089 5930.000 37.000 52.000 9.000 s4090 6680.000 44.000 60.000 10.000 s4091 6480.000 40.000 60.000 10.000 s4092 7230.000 47.000 68.000 11.000 s4093 6180.000 38.000 60.000 10.000 s4094 6930.000 45.000 68.000 11.000 s4095 6730.000 41.000 68.000 11.000 s4096 7480.000 48.000 76.000 12.000
parameter
UpperLimit(k) 'bounds'/
cost 10000 hours 100 people 50 /; upperlimit(k)$(upperlimit(k)=0) = INF; set infeas(s) 'infeasible solutions'; infeas(s) = sum(k$(f(s,k)>UpperLimit(k)),1); scalar numfeas 'number of feasible solutions'; numfeas = card(s)-card(infeas); display numfeas; * kill solutions that are not feasible x(infeas,i) = 0; f(infeas,k) = 0; |
---- 71 PARAMETER numfeas = 3473.000 number of feasible solutions
---- 87 PARAMETER f objective values cost hours people items s1 EPS EPS EPS EPS s2 750.000 7.000 8.000 1.000 s3 550.000 3.000 8.000 1.000 s4 1300.000 10.000 16.000 2.000 s5 250.000 1.000 8.000 1.000 s6 1000.000 8.000 16.000 2.000 s7 800.000 4.000 16.000 2.000
D:\projects>mcfilter
No
input file specified
Usage:
mcfilter xxx.gdx
mcfilter
will remove duplicate and dominated points in a
multi-criteria
solution set.
The
input is a gdx file with the following data:
parameter X(point, i): Points containing binary values.
If all zero for a
point, use EPS.
parameter F(point, obj): Objectives for
the points X.
If all zero for a
point, use EPS.
parameter S(obj): Direction of each objective:
1=max,-1=min
The
output will be a gdx file called xxx_res.gdx with the same parameters
but
without duplicates and dominated points.
D:\projects>
|
parameter sign(k) 'sign: -1:min, +1:max' /
(cost,hours,people) -1 items +1 /; execute_unload "feassols",x,f,sign=s; execute "mcfilter feassols.gdx"; |
mcfilter v3. Number of records = 3473 Number of X variables = 12 Number of F variables = 4 Loading GDX data = 15 ms After X Filter, count = 3473 X Duplicate filter = 0 ms After F Filter, count = 83 F Dominance filter = 0 ms Writing GDX data = 0 ms
 |
| Non-dominated solutions |
