In a post, the following question was posed:
We can select unique values \(\displaystyle\frac{1}{i}\) for \(i=1,\dots,n\). Find all combinations that add up to 1.
A complete enumeration scheme was slow even for \(n=10\). Can we use a MIP model for this or something related?
A single solution is easily found using the model:
| Mathematical Model |
|---|
| \[ \begin{align} & \sum_{i=1}^n \frac{1}{i} \cdot \color{darkred}x_i = 1 \\ & \color{darkred}x_i \in \{0,1\} \end{align}\] |
- Use a Constraint Programming (CP) tool. Most CP solvers have built-in facilities to return more than just a single solution. However, they also typically work with integer data. Few CP solvers allow fractional data. Here, we have fractional data by design. Converting to an integer problem can be done by scaling the constraint.
- Use a no-good constraint. Solve, add a constraint (cut) to the model that forbids the current solution, and repeat until things become infeasible.
- Some MIP solvers have what is called a solution pool which can enumerate solutions. These methods are often very fast.
- \(n=12\). This has three solutions.
- \(n=25\). This gives us 41 solutions.
Constraint programming
n=12 coefficients:[1.0, 0.5, 0.3333333333333333, 0.25, 0.2, 0.16666666666666666, 0.14285714285714285, 0.125, 0.1111111111111111, 0.1, 0.09090909090909091, 0.08333333333333333] number of solutions: 2 ['1/1'] ['1/2', '1/3', '1/6']
n=12, lcm=27720 coefficients:[27720, 13860, 9240, 6930, 5544, 4620, 3960, 3465, 3080, 2772, 2520, 2310] number of solutions: 3 ['1/1'] ['1/2', '1/3', '1/6'] ['1/2', '1/4', '1/6', '1/12']
n=25, lcm=26771144400 number of solutions: 41 ['1/1'] ['1/2', '1/3', '1/6'] ['1/2', '1/3', '1/8', '1/24'] ['1/2', '1/3', '1/9', '1/18'] ['1/2', '1/3', '1/10', '1/15'] ['1/2', '1/4', '1/5', '1/20'] ['1/2', '1/4', '1/6', '1/12'] ['1/2', '1/4', '1/8', '1/12', '1/24'] ['1/2', '1/4', '1/9', '1/12', '1/18'] ['1/2', '1/4', '1/10', '1/12', '1/15'] ['1/2', '1/5', '1/6', '1/12', '1/20'] ['1/2', '1/5', '1/8', '1/12', '1/20', '1/24'] ['1/2', '1/5', '1/9', '1/12', '1/18', '1/20'] ['1/2', '1/5', '1/10', '1/12', '1/15', '1/20'] ['1/2', '1/6', '1/8', '1/9', '1/18', '1/24'] ['1/2', '1/6', '1/8', '1/10', '1/15', '1/24'] ['1/2', '1/6', '1/9', '1/10', '1/15', '1/18'] ['1/2', '1/8', '1/9', '1/10', '1/15', '1/18', '1/24'] ['1/3', '1/4', '1/5', '1/6', '1/20'] ['1/3', '1/4', '1/5', '1/8', '1/20', '1/24'] ['1/3', '1/4', '1/5', '1/9', '1/18', '1/20'] ['1/3', '1/4', '1/5', '1/10', '1/15', '1/20'] ['1/3', '1/4', '1/6', '1/8', '1/12', '1/24'] ... ['1/4', '1/5', '1/6', '1/9', '1/10', '1/15', '1/18', '1/20'] ['1/4', '1/5', '1/8', '1/9', '1/10', '1/15', '1/18', '1/20', '1/24'] ['1/4', '1/6', '1/8', '1/9', '1/10', '1/12', '1/15', '1/18', '1/24'] ['1/5', '1/6', '1/8', '1/9', '1/10', '1/12', '1/15', '1/18', '1/20', '1/24']
No-good cuts
- Solve the model
- If infeasible: STOP
- Record the solution
- Add the no-good cut to the model
- Go to step 1
---- 75 PARAMETER trace results for each iteration 1/1 1/2 1/3 1/4 1/6 1/12 sum coeff 1.000 0.500 0.333 0.250 0.167 0.083 iter1 1.000 1.000 iter2 1.000 1.000 1.000 1.000 iter3 1.000 1.000 1.000 1.000 1.000
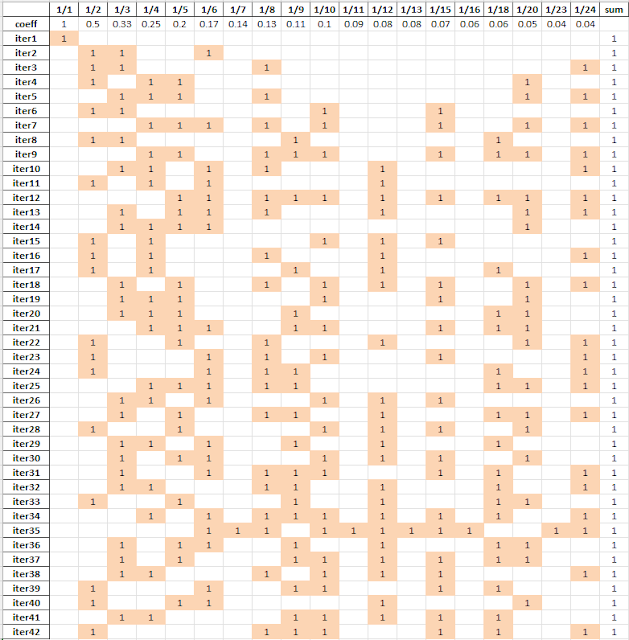

Cplex solution pool
--- Dumping 42 solutions from the solution pool...
Conclusion
- The constraint solver wants integer data, so I scaled the constraint by the LCM.
- The solve-loop with no-good constraints requires some attention. After scaling the constraint by 1000, I get the correct set of solutions
- The Cplex solution pool required me to change the integer feasibility tolerance.
References
- Python-constraint, https://pypi.org/project/python-constraint/
- Chess and Solution Pool, https://yetanothermathprogrammingconsultant.blogspot.com/2018/11/chess-and-solution-pool.html
Appendix: Python constraint code
import constraint as cp import math n = 25 r = range(1,1+n) lcm = math.lcm(*list(r)) print(f'n={n}, lcm={lcm}') # coefficients p = [lcm // i for i in r] if n <= 15: print(f'coefficients:{p}') problem = cp.Problem() problem.addVariables(r, [0,1]) problem.addConstraint(cp.ExactSumConstraint(lcm,p)) sol = problem.getSolutions() print(f'number of solutions: {len(sol)}') for k in sol: print([f'1/{i}' for i in k.keys() if k[i]==1])
Appendix: GAMS model
$onText
Enumerate feasible solutions 1. using no-good constraints 2. using Cplex solution pool $offText
*---------------------------------------------------------------- * data *----------------------------------------------------------------
set dummy 'for ordering of elements' /'coeff'/ i 'numbers 1/i to use' /'1/1'*'1/25'/ k0 'iterations (superset)' /iter1*iter100/ ;
parameter p(i) 'coefficients'; p(i) = 1/ord(i);
*---------------------------------------------------------------- * dynamic set + parameters to hold cut data *----------------------------------------------------------------
set k(k0) 'iterations performed (and cut data index)'; k(k0) = no;
parameter cutcoeff(k0,*) 'coefficients for cuts'; cutcoeff(k0,i) = 0;
*---------------------------------------------------------------- * model * no-good cuts are added after each solve *----------------------------------------------------------------
binary variable x(i); variable z 'obj'; Equations e 'sum to one' cuts 'no-good cuts' obj 'dummy objective' ;
scalar scale /1000/; e.. sum(i, scale*p(i)*x(i)) =e= scale; cuts(k).. sum(i,cutcoeff(k,i)*x(i)) =l= cutcoeff(k,'rhs'); obj.. z=e=0;
model m /all/; m.solprint = %solprint.Silent%; m.solvelink = %solveLink.Load Library%; option threads = 0;
*---------------------------------------------------------------- * algorithm *---------------------------------------------------------------- parameter trace(*,*) 'results for each iteration';
loop(k0,
solve m minimizing z using mip;
break$(m.modelstat <> 1 and m.modelstat <> 8); x.l(i) = round(x.l(i)); trace(k0,i) = x.l(i); cutcoeff(k0,i) = 2*x.l(i)-1; cutcoeff(k0,'rhs') = sum(i,x.l(i))-1; k(k0) = yes; );
trace('coeff',i)$sum(k,trace(k,i)) = p(i); trace(k,'sum') = sum(i,p(i)*trace(k,i)); display trace;
*---------------------------------------------------------------- * solution pool approach *----------------------------------------------------------------
model m2 /obj,e/; m2.optfile=1; solve m2 minimizing z using mip;
$onecho > cplex.opt * solution pool options solnpoolintensity 4 solnpoolpop 2 populatelim 10000 solnpoolmerge solutions.gdx
* tighten tolerances epint 0 $offecho
* * load the gdx file with all solutions * set id /soln_m2_p1*soln_m2_p1000/; parameter xsol(id,i); execute_load "solutions.gdx",xsol=x; display xsol;
|
Just using the pre-computed LCM values from OEIS, the following MiniZinc model takes 1.2 seconds to find all 41 solutions for n=25 with the OR-Tools solver. I use MiniZinc 2.7.4, OR-Tools version 9.4 with one thread, and running on Macbook M1 Max. using multiple threads did not help in enumeration speed.
ReplyDelete```
int: n;
set of int: N = 1..n;
% LCM of first n natural numbers, A003418 in OEIS. https://oeis.org/A003418
array[int] of int: A003418 = [1, 1, 2, 6, 12, 60, 60, 420, 840, 2520, 2520, 27720, 27720, 360360, 360360, 360360, 720720, 12252240, 12252240, 232792560, 232792560, 232792560, 232792560, 5354228880, 5354228880, 26771144400, 26771144400, 80313433200, 80313433200, 2329089562800, 2329089562800];
int: lcm = A003418[n];
array[N] of var bool: used;
constraint sum(i in N) ( if used[i] then (lcm div i) else 0 endif ) = lcm;
solve satisfy;
output [join(" + ", ["1/\(i)" | i in N where fix(used[i])])];
```
The relevant statistics at the end are
```
%%%mzn-stat: nSolutions=41
%%%mzn-stat: boolVariables=75
%%%mzn-stat: failures=58188
%%%mzn-stat: propagations=1131906
%%%mzn-stat: solveTime=1.13089
```
The Gecode solver works up to size 23, since it uses 32-bit integers. At size 23, Gecode takes 0.3s to find all 22 solutions, and OR-Tools takes 0.4s.
Solving for larger cases with OR-Tools:
* size 26 takes 1.3s to find all 41 solutions
* size 27 takes 6.5s to find all 41 solutions
* size 28 takes 3.7s to find all 114 solutions
* size 29 takes 44s to find all 114 solutions
* size 30 takes 12s to find all 200 solutions
* size 31 takes 33s to find all 200 solutions
I have not tried to verify these results for correctness.
Mikael, those counts are correct. See https://oeis.org/A092670.
DeleteThanks Rob! Naturally it is in OEIS as well :-)
Delete