Notation
Data
- GRADE: dependent variable indicating better grades in later economics classes,
- PSI: use of new teaching method (Personalized System of Instruction),
- GPA: Grade Point Average,
- TUCE: test score on the subject before entering the class
| Data |
|---|
OBS GPA TUCE PSI GRADE 1 2.66 20 0 0 2 2.89 22 0 0 3 3.28 24 0 0 4 2.92 12 0 0 5 4.00 21 0 1 6 2.86 17 0 0 7 2.76 17 0 0 8 2.87 21 0 0 9 3.03 25 0 0 10 3.92 29 0 1 11 2.63 20 0 0 12 3.32 23 0 0 13 3.57 23 0 0 14 3.26 25 0 1 15 3.53 26 0 0 16 2.74 19 0 0 17 2.75 25 0 0 18 2.83 19 0 0 19 3.12 23 1 0 20 3.16 25 1 1 21 2.06 22 1 0 22 3.62 28 1 1 23 2.89 14 1 0 24 3.51 26 1 0 25 3.54 24 1 1 26 2.83 27 1 1 27 3.39 17 1 1 28 2.67 24 1 0 29 3.65 21 1 1 30 4.00 23 1 1 31 3.10 21 1 0 32 2.39 19 1 1 |
Data Prep
---- 79 PARAMETER y dependent variable (grade) case5 1.000, case10 1.000, case14 1.000, case20 1.000, case22 1.000, case25 1.000, case26 1.000 case27 1.000, case29 1.000, case30 1.000, case32 1.000 ---- 79 PARAMETER X independent variables constant gpa tuce psi case1 1.000 2.660 20.000 case2 1.000 2.890 22.000 case3 1.000 3.280 24.000 case4 1.000 2.920 12.000 case5 1.000 4.000 21.000 case6 1.000 2.860 17.000 case7 1.000 2.760 17.000 case8 1.000 2.870 21.000 case9 1.000 3.030 25.000 case10 1.000 3.920 29.000 case11 1.000 2.630 20.000 case12 1.000 3.320 23.000 case13 1.000 3.570 23.000 case14 1.000 3.260 25.000 case15 1.000 3.530 26.000 case16 1.000 2.740 19.000 case17 1.000 2.750 25.000 case18 1.000 2.830 19.000 case19 1.000 3.120 23.000 1.000 case20 1.000 3.160 25.000 1.000 case21 1.000 2.060 22.000 1.000 case22 1.000 3.620 28.000 1.000 case23 1.000 2.890 14.000 1.000 case24 1.000 3.510 26.000 1.000 case25 1.000 3.540 24.000 1.000 case26 1.000 2.830 27.000 1.000 case27 1.000 3.390 17.000 1.000 case28 1.000 2.670 24.000 1.000 case29 1.000 3.650 21.000 1.000 case30 1.000 4.000 23.000 1.000 case31 1.000 3.100 21.000 1.000 case32 1.000 2.390 19.000 1.000
Exercise

OLS: Ordinary Least Squares
| QP Model 1 |
|---|
| \[\begin{align}\min&\sum_i \color{darkred}e_i^2 \\& \color{darkblue}y_i = \sum_j \color{darkblue}X_{i,j} \color{darkred}\beta_j + \color{darkred}e_i &&\forall i \end{align}\] |
These are easy models, and they can be solved with any QP or NLP solver. We can substitute out \(\color{darkred}e_i\), and a more standard unconstrained QP follows:
| Unconstrained QP Model 2 |
|---|
| \[\min\>\sum_i \left(\color{darkblue}y_i - \sum_j \color{darkblue}X_{i,j} \color{darkred}\beta_j\right)^2 \] |
| OLS Normal Equations |
|---|
| \[(\color{darkblue}X'\color{darkblue}X)\color{darkred}\beta = \color{darkblue}X'\color{darkblue}y\] |
In GAMS, systems of equations can be solved as CNS (Constrained Nonlinear System) or MCP (Mixed Complementarity Problem) or using an LP/NLP with a dummy objective. Note that this method is numerically not very stable: when forming \((\color{darkblue}X'\color{darkblue}X)\) some very large numbers may be created.
---- 356 PARAMETER results results from estimation methods OLS(QP1) OLS(QP2) OLS(NRML) OLS(py) coeff coeff coeff coeff constant -1.498 -1.498 -1.498 -1.498 gpa 0.464 0.464 0.464 0.464 tuce 0.010 0.010 0.010 0.010 psi 0.379 0.379 0.379 0.379
Logit and Probit Models
| Logit Log Likelihood |
|---|
| \[\max \ln \color{darkred}L = \sum_i \left\{\color{darkblue}y_i {\color{darkblue}{\bf x}}_i'{\color{darkred}\beta} - \ln\left[1+\exp({\color{darkblue}{\bf x}}_i'{\color{darkred}\beta})\right]\right\}\] |
| Logit First-Order Conditions |
|---|
| \[\sum_i \left[ \left(\color{darkblue}y_i-\frac{\exp({\color{darkblue}{\bf x}}_i'{\color{darkred}\beta})}{1+\exp({\color{darkblue}{\bf x}}_i'{\color{darkred}\beta})} \right) \color{darkblue}X_{i,j}\right] = 0 \>\>\>\forall j \] |
| Probit Log Likelihood |
|---|
| \[\max \ln\color{darkred}L = \sum_i \left\{\color{darkblue}y_i \ln \Phi({\color{darkblue}{\bf{x}}}_i'{\color{darkred}{\bf{\beta}}}) + (1-\color{darkblue}y_i) \ln(1- \Phi({\color{darkblue}{\bf{x}}}_i'{\color{darkred}{\bf{\beta}}})) \right\}\] |
where \(\Phi(.)\) is the error function. Not much simplification we can do here.

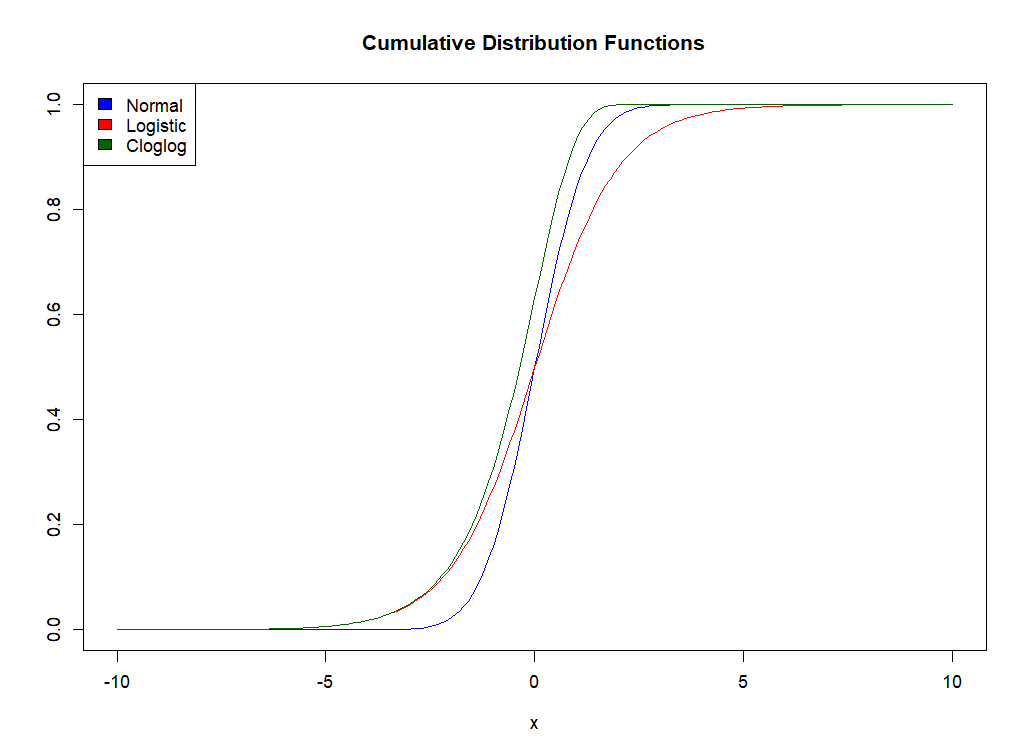
---- 497 PARAMETER results replicate Greene table 17.1 OLS(QP1) OLS(QP2) OLS(NRML) OLS(py) LOGIT1 coeff coeff coeff coeff coeff constant -1.498 -1.498 -1.498 -1.498 -13.021 gpa 0.464 0.464 0.464 0.464 2.826 tuce 0.010 0.010 0.010 0.010 0.095 psi 0.379 0.379 0.379 0.379 2.379 + LOGIT2 LOGIT PROBIT PROBIT CLOGLOG coeff APE coeff APE coeff constant -13.021 -7.452 -10.031 gpa 2.826 0.363 1.626 0.361 2.294 tuce 0.095 0.012 0.052 0.011 0.041 psi 2.379 0.358 1.426 0.374 1.562 mean f(x'b) 0.128 0.222 + CLOGLOG APE gpa 0.413 tuce 0.007 psi 0.312 mean f(x'b) 0.180
Why log-likelihood?
- The probit model, with \(F(x)=\Phi(x)\) (i.e., the error function).
- Initial values for the coefficients: 0. This is the same as for the previous models.
---- 546 initial point ---- 546 VARIABLE coeff.L estimated coefficients ( ALL 0.000 ) ---- 548 final point ---- 548 VARIABLE coeff.L estimated coefficients ( ALL 0.000 )
---- like =E= like.. (1.85771975853216E-9)*coeff(constant) + (4.50125497492343E-9)*coeff(gpa) + (3.41820435569918E-8)*coeff(tuce) - (3.71543951706432E-10)*coeff(psi) + likelihood =E= 0 ; (LHS = -2.3283064365387E-10, INFES = 2.3283064365387E-10 ****)
---- probitObj =E= log likehood for Probit model probitObj.. (7.97884560802865)*coeff(constant) + (19.3327429082534)*coeff(gpa) + (146.810759187727)*coeff(tuce) - (1.59576912160573)*coeff(psi) + lnL =E= 0 ; (LHS = 9.29107555578682, INFES = 9.29107555578682 ****)
Note that the INFES numbers in these sections are not something to worry about. This means that for the initial point coeff, the current values of likelihood and lnL are not correct. As this is the objective function, that is not an issue: the objective variable will be substituted out before solving starts.
Conclusion
- Different formulations/tools for linear regression.
- Max log likelihood formulations for logit, probit, and complementary log log models.
- Implementation of partial effects (a.k.a. marginal effects).
- Issues with maximizing the likelihood function directly.
References
- William Greene, Econometric Analysis, 8th edition, 2017. Chapter 17, Binary Outcomes and Discrete Choices.
- Spector, Lee C., and Michael Mazzeo. “Probit Analysis and Economic Education.” The Journal of Economic Education 11, no. 2 (1980): 37–44.
Appendix: GAMS model
|
$ontext |
No comments:
Post a Comment