argmax(w) sum(sign(Aw) == sign(b))
This is a strange objective. Basically: find \(w\), with \(v=Aw\) such that we maximize the number of \(v_i\) having the same sign as \(b_i\). I have never seen such an objective.
As \(A\) and \(b\) are constants, we can precompute \[ \beta_i = \mathrm{sign}(b_i)\] This simplifies the situation a little bit (but I will not need it below).
A different way to say "\(v_i\) and \(b_i\) have the same sign" is to state: \[ v_i b_i > 0 \] I assumed here \(b_i \ne 0\). Similarly, the constraint \( v_i b_i < 0\) means: "\(v_i\) and \(b_i\) have the opposite sign."
If we introduce binary variables: \[\delta_i = \begin{cases} 1 & \text{if $ v_i b_i > 0$}\\ 0 & \text{otherwise}\end{cases}\] a model can look like: \[\begin{align} \max & \sum_i \delta_i \\ &\delta_i =1 \Rightarrow \sum_j a_{i,j} b_i w_j > 0 \\ & \delta_i \in \{0,1\}\end{align}\] The implication can be implemented using indicator constraints, so we have now a linear MIP model.
Notes:
- I replaced the \(\gt\) constraint by \(\sum_j a_{i,j} b_i w_j \ge 0.001\)
- If the \(b_i\) are very small or very large we can replace them by \(\beta_i\), i.e. \(\sum_j a_{i,j} \beta_i w_j \gt 0\)
- The case where some \(b_i=0\) is somewhat ignored here. In this model, we assume \(\delta_i=0\) for this special case.
- We can add explicit support for \(b_i=0\) by: \[\begin{align} \max & \sum_i \delta_i \\ &\delta_i =1 \Rightarrow \sum_j a_{i,j} b_i w_j > 0 && \forall i | b_i\ne 0 \\ & \delta_i =1 \Rightarrow \sum_j a_{i,j} w_j = 0 && \forall i | b_i = 0 \\ & \delta_i \in \{0,1\}\end{align}\]
- We could model this with binary variables or SOS1 variables. Binary variables require big-M values. It is not always easy to find good values for them. The advantage of indicator constraints is that they allow an intuitive formulation of the problem while not using big-M values.
- Many high-end solvers (Cplex, Gurobi, Xpress, SCIP) support indicator constraints. Modeling systems like AMPL also support them.
Test with small data set
Let's do a test with a small random data set.
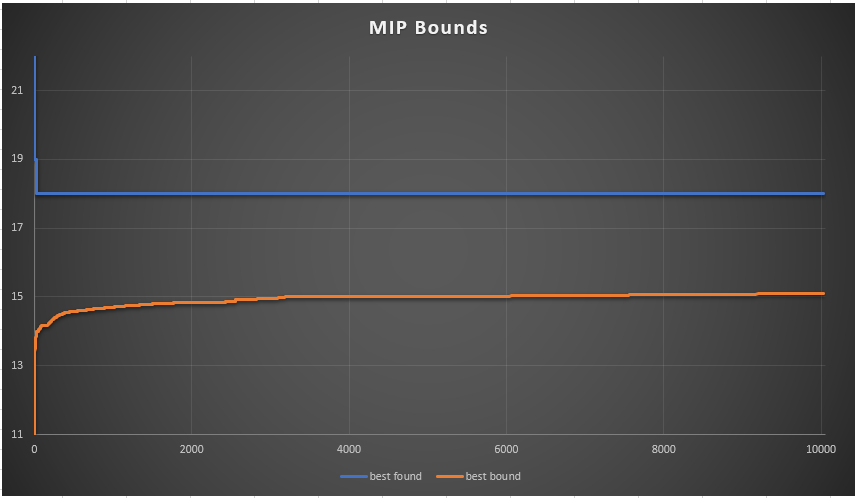
---- 17 PARAMETER a random matrix j1 j2 j3 j4 j5 i1 -0.657 0.687 0.101 -0.398 -0.416 i2 -0.552 -0.300 0.713 -0.866 4.213380E-4 i3 0.996 0.157 0.982 0.525 -0.739 i4 0.279 -0.681 -0.500 0.338 -0.129 i5 -0.281 -0.297 -0.737 -0.700 0.178 i6 0.662 -0.538 0.331 0.552 -0.393 i7 -0.779 0.005 -0.680 0.745 -0.470 i8 -0.428 0.188 0.445 0.256 -0.072 i9 -0.173 -0.765 -0.372 -0.907 -0.323 i10 -0.636 0.291 0.121 0.540 -0.404 i11 0.322 0.512 0.255 -0.432 -0.827 i12 -0.795 0.283 0.091 -0.937 0.585 i13 -0.854 -0.649 0.051 0.500 -0.644 i14 -0.932 0.170 0.242 -0.221 -0.283 i15 -0.514 -0.507 -0.739 0.867 -0.240 i16 0.567 -0.400 -0.749 0.498 -0.862 i17 -0.596 -0.990 -0.461 -2.97050E-4 -0.697 i18 -0.652 -0.339 -0.366 -0.356 0.928 i19 0.987 -0.260 -0.254 0.544 -0.207 i20 0.826 -0.761 0.471 -0.889 0.153 i21 -0.897 -0.988 -0.198 0.040 0.258 i22 -0.549 -0.208 -0.448 -0.695 0.873 i23 -0.155 -0.731 -0.228 -0.251 -0.463 i24 0.897 -0.622 -0.405 -0.851 -0.197 i25 -0.797 -0.232 -0.352 -0.616 -0.775 ---- 17 PARAMETER b random rhs i1 0.193, i2 0.023, i3 -0.910, i4 0.566, i5 0.891, i6 0.193, i7 0.215, i8 -0.275 i9 0.188, i10 0.360, i11 0.013, i12 -0.681, i13 0.314, i14 0.048, i15 -0.751, i16 0.973 i17 -0.544, i18 0.351, i19 0.554, i20 0.865, i21 -0.598, i22 -0.406, i23 -0.606, i24 -0.507 i25 0.293 ---- 17 PARAMETER beta sign of b i1 1.000, i2 1.000, i3 -1.000, i4 1.000, i5 1.000, i6 1.000, i7 1.000, i8 -1.000 i9 1.000, i10 1.000, i11 1.000, i12 -1.000, i13 1.000, i14 1.000, i15 -1.000, i16 1.000 i17 -1.000, i18 1.000, i19 1.000, i20 1.000, i21 -1.000, i22 -1.000, i23 -1.000, i24 -1.000 i25 1.000 ---- 53 VARIABLE w.L j1 -0.285, j2 -0.713, j3 -0.261, j4 -0.181, j5 -0.630 ---- 53 PARAMETER v sum(j, a(i,j)*w(j)) i1 0.005, i2 0.342, i3 -0.282, i4 0.556, i5 0.498, i6 0.256, i7 0.557, i8 -0.129 i9 1.059, i10 0.099, i11 0.076, i12 -0.197, i13 1.008, i14 0.299, i15 0.695, i16 0.771 i17 1.435, i18 0.003, i19 0.002, i20 0.249, i21 0.843, i22 -0.002, i23 0.962, i24 0.571 i25 1.084 ---- 53 VARIABLE delta.L i1 1.000, i2 1.000, i3 1.000, i4 1.000, i5 1.000, i6 1.000, i7 1.000, i8 1.000 i9 1.000, i10 1.000, i11 1.000, i12 1.000, i13 1.000, i14 1.000, i16 1.000, i18 1.000 i19 1.000, i20 1.000, i22 1.000, i25 1.000 ---- 53 VARIABLE z.L = 20.000 objective variable
This means, for this 25 row problem we can find \(w\)'s such that 20 rows yield the same sign as \(b_i\).
References
- SCIP What is the function for sign?, https://stackoverflow.com/questions/53030430/scip-what-is-the-function-for-sign