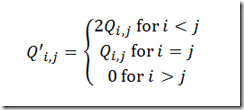In http://www.improbable.com/2012/02/12/finding-an-optimal-seating-chart-for-a-wedding/ an interesting model is proposed about optimal seating arrangements for a wedding. Basically their model looks like (I hope I transcribed the mathematical model correctly):
| $ontext
Table assignment
This is the original formulation used in
Meghan L. Bellows
and J. D. Luc Peterson
Finding an optimal seating chart
http://www.improbable.com/2012/02/12/finding-an-optimal-seating-chart-for-a-wedding/
See also:
http://www.hakank.org/constraint_programming_blog/
2011/03/a_matching_problem_a_related_seating_problem_and_some_other_seating_pr.html
$offtext
set
i 'tables' /table1*table5/
j 'guests' /g1*g17/
;
alias (j,k);
table c(j,k)
g1 g2 g3 g4 g5 g6 g7 g8 g9 g10 g11 g12 g13 g14 g15 g16 g17
g1 1 50 1 1 1 1 1 1 1
g2 50 1 1 1 1 1 1 1 1
g3 1 1 1 50 1 1 1 1 10
g4 1 1 50 1 1 1 1 1 1
g5 1 1 1 1 1 50 1 1 1
g6 1 1 1 1 50 1 1 1 1
g7 1 1 1 1 1 1 1 50 1
g8 1 1 1 1 1 1 50 1 1
g9 1 1 10 1 1 1 1 1 1
g10 1 50 1 1 1 1 1 1
g11 50 1 1 1 1 1 1 1
g12 1 1 1 1 1 1 1 1
g13 1 1 1 1 1 1 1 1
g14 1 1 1 1 1 1 1 1
g15 1 1 1 1 1 1 1 1
g16 1 1 1 1 1 1 1 1
g17 1 1 1 1 1 1 1 1
;
scalars
a 'max guests at a table' / 4 /
b 'min number of guests known at table' / 2 /
variables
g(i,j) 'guest j at table i'
p(i,j,k) 'guest j and k at table i'
z
;
binary variable g,p;
equations
obj
onetable(j)
capacity(i)
minknown(i,k)
linearize1(i,k)
linearize2(i,j)
;
set gt(j,k) 'upper triangle';
gt(j,k)$(ord(k)>ord(j)) = yes;
obj.. z =e= sum((i,gt(j,k)), c(j,k)*p(i,j,k));
onetable(j).. sum(i, g(i,j)) =e= 1;
capacity(i).. sum(j, g(i,j)) =l= a;
minknown(i,k).. sum(j$c(j,k), p(i,j,k)) =g= (b+1)*g(i,k);
linearize1(i,k).. sum(j, p(i,j,k)) =l= a*g(i,k);
linearize2(i,j).. sum(k, p(i,j,k)) =l= a*g(i,j);
model m /all/;
option optcr = 0;
solve m maximizing z using mip;
option g:0;
display g.l;
|
I would probably formulate this slightly different. A linearization

is often formulated as:

Here the last condition can be dropped as we are maximizing the p’s anyway. In general I use these disaggregated versions directly instead of the aggregated versions used in model above.
So how would I write this down? Here is my attempt:
| $ontext
Table assignment
This is a reformulation of the original model
Meghan L. Bellows
and J. D. Luc Peterson
Finding an optimal seating chart
http://www.improbable.com/2012/02/12/finding-an-optimal-seating-chart-for-a-wedding/
See also:
http://www.hakank.org/constraint_programming_blog/2011
/03/a_matching_problem_a_related_seating_problem_and_some_other_seating_pr.html
$offtext
set
t 'tables' /table1*table5/
g 'guests' /g1*g17/
;
alias (g,g1,g2);
table c(g1,g2)
g1 g2 g3 g4 g5 g6 g7 g8 g9 g10 g11 g12 g13 g14 g15 g16 g17
g1 1 50 1 1 1 1 1 1 1
g2 50 1 1 1 1 1 1 1 1
g3 1 1 1 50 1 1 1 1 10
g4 1 1 50 1 1 1 1 1 1
g5 1 1 1 1 1 50 1 1 1
g6 1 1 1 1 50 1 1 1 1
g7 1 1 1 1 1 1 1 50 1
g8 1 1 1 1 1 1 50 1 1
g9 1 1 10 1 1 1 1 1 1
g10 1 50 1 1 1 1 1 1
g11 50 1 1 1 1 1 1 1
g12 1 1 1 1 1 1 1 1
g13 1 1 1 1 1 1 1 1
g14 1 1 1 1 1 1 1 1
g15 1 1 1 1 1 1 1 1
g16 1 1 1 1 1 1 1 1
g17 1 1 1 1 1 1 1 1
;
scalars
a 'max guests at a table' / 4 /
b 'min number of guests known at table' / 2 /
variables
x(g,t) 'guest at table '
meet(g1,g2) 'guests g1 and g2'
meetex(g1,g2,t) 'guests g1 and g2 at table t'
z
;
binary variable x,meet,meetex;
set gt(g1,g2) 'upper triangle';
gt(g1,g2)$(ord(g2)>ord(g1)) = yes;
meet.prior(gt(g1,g2)) = INF;
meetex.prior(gt(g1,g2),t) = INF;
equations
obj
onetable(g)
capacity(t)
minknown(g)
defmeet(g,g)
linearize1(g,g,t)
linearize2(g,g,t)
;
obj.. z =e= sum(gt(g1,g2), c(g1,g2)*meet(g1,g2));
onetable(g).. sum(t, x(g,t)) =e= 1;
capacity(t).. sum(g, x(g,t)) =l= a;
minknown(g1).. sum(gt(g1,g2)$c(g1,g2), meet(g1,g2)) + sum(gt(g2,g1)$c(g2,g1), meet(g2,g1)) =g= b;
defmeet(gt(g1,g2)).. meet(g1,g2) =e= sum(t, meetex(g1,g2,t));
linearize1(gt(g1,g2),t).. meetex(g1,g2,t) =l= x(g1,t);
linearize2(gt(g1,g2),t).. meetex(g1,g2,t) =l= x(g2,t);
x.fx('g1','table1') = 1;
model m /all/;
option optcr = 0;
solve m maximizing z using mip;
option x:0;
display x.l;
|
I renamed some of the sets and variables.
A further improvement is that we fix guest 1 to table 1. This reduces the symmetry in the model.
So which model performs better? Of course this is only one data set, so we need to be careful not to read to much into this, but here are the results with GAMS and Cplex 12.3:
| | original model | reformulation |
| equations | 278 | 1536 |
| variables | 1531 | 902 |
| binary variables | 1530 | 84 |
| optimal objective | 226 | 226 |
| solution time | 216 seconds
(reported in paper: 2 seconds) | 0.4 seconds |
| iterations/nodes | 3502605 iterations, 93385 nodes | 6943 iterations, 180 nodes |
It looks like the performance of the original model is much slower than reported in the paper. I don’t know the reason for that, may be the GAMS model contained a few tricks not mentioned in the description of the mathematical model (may be related to symmetry when comparing guest j against guest k). Another reason may be that in the paper it is mentioned that some serious server hardware is used while I am running on one thread on a laptop.
Of course this model can also be formulated as a Constraint Programming model. In http://hakank.org/minizinc/wedding_optimal_chart.mzn a single integer variable Tables[guest] for each guest is used indicating the table number. Furthermore using CP constructs one can reduce the model to basically one block of equations:
forall(i in 1..n) (
sum(j in 1..m) (bool2int(tables[j] = i)) >= b
/\
sum(j in 1..m) (bool2int(tables[j] = i)) <= a
)
|
In the MIP model we have to do a little bit more work!
Note that the CP formulation is probably incorrect w.r.t. to the minimum number of known people at a table (parameter b).
Update: The CP model is fixed. The advantage of using modeling languages is that other people can read the model. If this would be some C++ code I would not have bothered to try to understand it. Also it is often argued that a modeling language helps in maintaining models as fixes are easier to identify and implement than in a traditional programming language.